Meet Akira,
Always here to listen and talk.
Always on your side.
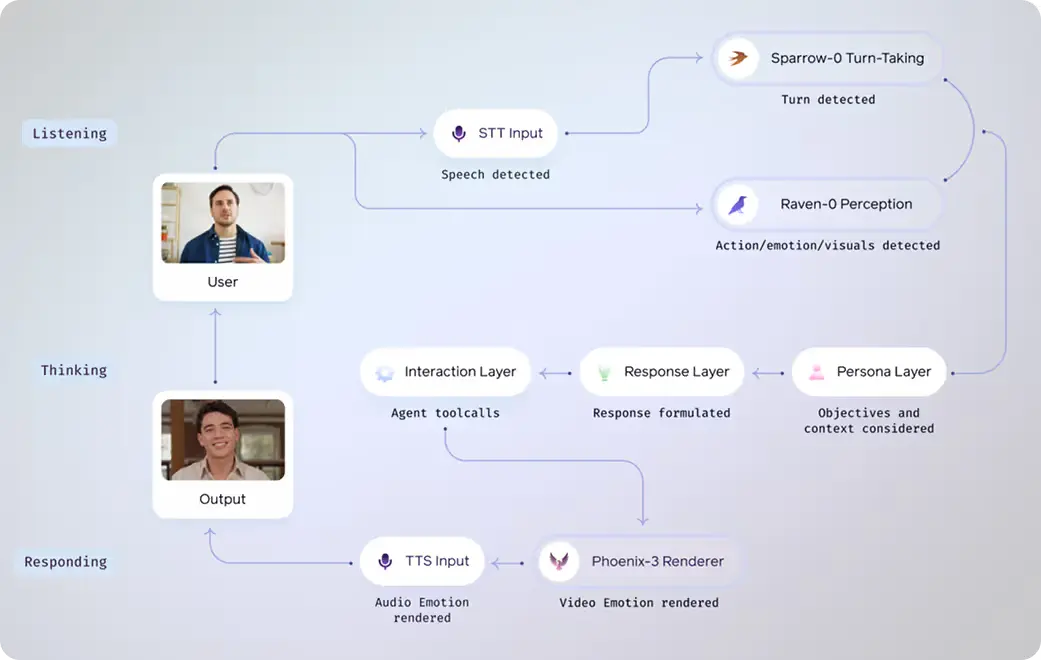
Akira mirrors how people see, think, and respond, in real time.
By combining facial rendering, vision, speech, and emotional intelligence, our human simulation models enable face-to-face AI conversations that capture intent, nuance, and presence.
Responses land in under 600 ms, with data retrieval in 30 ms, up to 15× faster than leading RAG systems.
Enjoy conversational experiences with Akira that looks & feels human.
Try our Conversational Video Interface.
Akira understands the rhythm of conversation, analyzes tone, pacing, and intent to engage naturally, pausing, interrupting, and responding with human-like timing. She continuously processing visual context, reading emotions, and responding intelligently to its environment.
Our real-time human simulation models let machines see, process visual context, read emotions, hear, respond, and even look real, enabling meaningful face-to-face conversations with people.
Powered by the most advanced full-face rendering model ever built, Akira has natural facial movements, micro-expressions, and real-time emotional response, making her feel truly present.
Akira can see, reads expressions, visual cues, and the environment to engage in a realistic, nuanced way.
Whether you need someone to celebrate with or a shoulder to lean on, Akira is available 24/7 with natural voice conversations and genuine emotional support.